목차
1. 주제
2. TTS
3. BackEnd
4. TeamLeader
5. 마치며
1년간 진행한 졸업프로젝트 기술 정리 및 회고록
2021년 9월부터 2022년 6월(진행 중)까지 진행되었던 졸업프로젝트 개발이 끝났다. 나는 졸업프로젝트에서 TTS와 백엔드, 팀장을 맡았다.
이 글에서는TTS->백엔드->팀장의 순으로 기술 설명과 졸업프로젝트 후기를 적어보려 한다.
주제
우리 팀은 소멸위기에 처한 사투리를 보전하기 위한 제주어 사투리 오디오북, 코소롱을 주제로 프로젝트를 진행했고 TTS와 기계번역 딥러닝 모델을 제주어 데이터셋으로 학습시키고 이를 통해 사투리 오디오북을 제작해주는 웹 서비스를 만들었다.
TTS
TTS는 입력된 텍스트를 음성으로 바꾸는 것이다. (Text To Speech)
Tacotron 등 다양한 딥러닝 기반 TTS가 있는데 우리는 Glow-TTS로 학습을 진행했다. Glow-TTS는 mximum likelihood 자체를 활용해 학습에 사용하였으며 alignment를 잘 찾는다는 특성을 가진다.
Glow-TTS
Glow-TTS는 Tacotron2보다 높은 속도를 가지고 있으며 입력 문장과 발화 사이의 가장 probable한 monotonic alignment를 찾는다.
Training and Inference Procedures
우리의 목표는 데이터의 log-liklihood를 최대화하는 alignment A와 파라미터 θ를 찾는 것이다.
이때, global solution을 찾는 것이 어렵기 때문에 목표를 두 단계로 나눈다.
- 현재 파라미터 θ에 대해 가장 probable한 monotonic alignment A∗를 찾는다.
- log-likelihood를 최대화하도록 파라미터 θ를 업데이트한다.
FastSpeech의 구조를 따라서 duration predictor를 text encoder 앞에 두었고 logarithmic domain에서 MSE로 학습시켰다.
또한 duration predictor가 maximum likelihood에 영향을 끼치지 않도록 backward pass에서 stop gradient operator를 적용하여 gradient를 지웠다.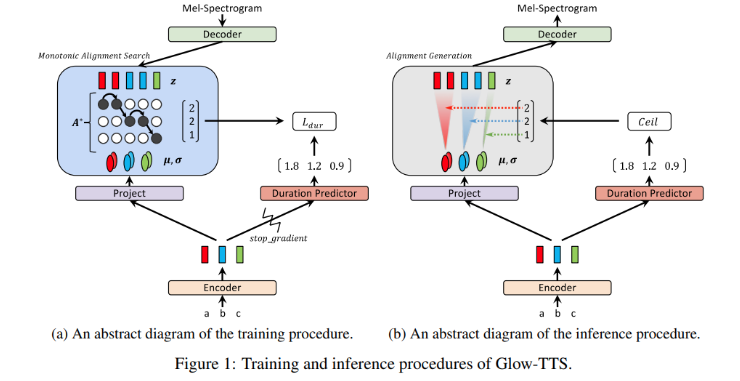 Monotonic Alignment SearchMonotonic Alignment Search(MAS)는 아래 그림과 같은 알고리즘으로 진행된다.
Monotonic Alignment SearchMonotonic Alignment Search(MAS)는 아래 그림과 같은 알고리즘으로 진행된다. Model ArchitectureGlow-TTS의 가장 핵심적인 부분이 바로
Model ArchitectureGlow-TTS의 가장 핵심적인 부분이 바로 flow-based decoder이다.
Decoder는normalization layer,invertible 1x1 conv layer,affine coupling layer로 이루어진 multiple block 여러 개로 구성되어 있다.Encoder & Duration PredictorEncoder의 구조는 Transformer TTS와 유사하지만, 두가지의 차이가 있다. - Decoder
Self-attention모듈에 postional encoding 대신 relative position representation을 넣었다.encoder pre-net에 residual connection을 추가했다.
Duration predictor는 conv layer 2개, ReLU, normalization layer, dropout, projection layer로 이루어져 있다.
학습 방법
우리는 구글 코랩과 구글 드라이브, 제주어 음성과 텍스트가 1대1로 매칭된 데이터셋을 이용해 학습을 진행하였다.
먼저 코랩 환경에 GPU런타임과 구글드라이브 마운트가 되어있는 상태에서 아래 셀들을 실행해야 한다.
1. 필수 라이브러리 및 함수 불러오기
# Change CUDA version to 10.1
!rm /usr/local/cuda
!ln -s /usr/local/cuda-10.1 /usr/local/cuda
# check if installed successfully
!nvcc --versionimport sys
from pathlib import Path
from pprint import pprint
!nvidia-smi%tensorflow_version 2.x%cd /content
!git clone --depth 1 https://github.com/sce-tts/glow-tts.git
%cd /content/glow-tts
!pip install -q --no-cache-dir "torch==1.5.1" -f https://download.pytorch.org/whl/cu101/torch_stable.html
!pip install -q --no-cache-dir "cython==0.29.12" "librosa==0.6.0" "numpy==1.16.4" "scipy==1.3.0" "numba==0.48" "Unidecode==1.0.22" "tensorflow==2.3.0" "inflect==4.1.0" "matplotlib==3.3.0"%cd /content
!git clone https://github.com/NVIDIA/apex /content/apex
%cd /content/apex
!git checkout 37cdaf4
!pip install -q --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" .%cd /content/glow-tts/monotonic_align
!python setup.py build_ext --inplace2. 학습할 데이터셋을 구글 드라이브에서 불러오기
%cd /content/glow-tts
# !gdown --id 1UpoBaZRTJXkTdsoemLBWV48QClm6hpTX -O filelists.zip
!cp "/content/drive/My Drive/Colab Notebooks/data/filelists.zip" ./filelists.zip
!rm -rf ./filelists
!unzip -q filelists.zip -d ./filelists3. 사전 학습 데이터 불러오기
체크 포인트를 이어서 학습할 수 있도록 해준다.
%cd /content/glow-tts
!mkdir -p "/content/drive/My Drive/Colab Notebooks/data/glow-tts"4. 학습 진행
학습이 정상적으로 진행된다면 사용자가 멈추기 전까진 셀이 종료되지 않고 계속 실행된다. 학습이 진행되면 드라이브에 체크포인트가 생성된다. 학습을 종료시킨 후 다시 처음부터 진행한다면 구글 드라이브에 저장된 가장 최근 체크포인트를 기준으로 학습이 다시 시작된다.
!pip install unidecode
%cd /content/glow-tts
!python init.py -c configs/base.json -m "/content/drive/My Drive/Colab Notebooks/data/glow-tts"
!python train.py -c configs/base.json -m "/content/drive/My Drive/Colab Notebooks/data/glow-tts"학습 결과
약 1000회 정도의 학습을 진행했고 그 결과는 다음과 같다.
음성 들으려면 클릭!

약간 매끄럽지 못한 부분도 있지만 "
합니다" 등의 어미 같은 부분의 억양을 나름 잘 살렸다고 생각한다. ~
(???: 니 새끼 너나 예쁘지 🥲)~~
백엔드
다음은 백엔드 파트이다. 우리는 딥러닝 서버와 API 서버를 나눠서 제작했고 딥러닝 서버에는 flask, API 서버에는 Django를 사용했다. 두 서버를 나눠서 제작한 이유는 처음에 딥러닝 서버를 만들 때 여러 어려움에 봉착했고... 프로젝트를 빠르게 진행하기 위해서 API 서버와 딥러닝 서버를 다른 팀원과 역할을 나눠서 만들게 됐기 때문이고... 또 다른 이유는 딥러닝 서버가 아무래도 무겁기 때문에 빠르고 가볍게 개발할 수 있는 부분은 따로 분리해서 개발하는 게 좋겠다는 판단이 들었기 때문이다.
Django
나는 두 부분 중에서 API 서버를 집중적으로 맡았다.
사실 유저 관리와 같은 부분도 만들긴 했는데 교수님이나 다른 분들께서 시간이 모자라면 그런 부분은 빼고 메인 기능에 집중하라고 하셨고... 뭐 그런 이유때문에 그런 부가 기능들은 백엔드만 있고 프로젝트에서 실제로 구현되진 않았다.
클래스형 view (CBV)
클래스형 뷰는 클래스로 작성되어 있는 뷰 객체를 말하는 것으로, 뷰의 체계적인 관리가 가능하다.
나는 코드 구조를 깔끔하게 하기 위해 클래스형 view로 개발했다.함수형 뷰의 경우 if 문을 통해 함수 내에서 HTTP Method를 구분해주어야 하지만 클래스형 뷰의 경우에는 클래스 내부에 HTTP Method 별로 각각의 함수를 만들게 되기 때문에 보다 깔끔한 개발이 가능하다.
또한 클래스형 뷰는 제네릭 뷰를 사용하여 자주 사용하는 기능을 미리 구현해두고 상속받을 수 있기 때문에 기능을 짜임새 있게 만들 수 있다.
- view.py
class BookView(View):
def get(self, request, book_id):
book = get_object_or_404(Book, pk=book_id)
return JsonResponse(
{
"id" : book.pk,
"title" : book.title,
"content" : book.content,
"audio" : book.audio,
}, status=200
)
def delete(self, request, book_id):
book = get_object_or_404(Book, pk=book_id)
book.delete()
return JsonResponse({"MESSAGE": "SUCCESS"}, status=204)
- urls.py
path에 view이름 뒤에 as_view()를 붙여주자.
from django.urls import path
from books.views import (
BookView,
)
urlpatterns = [
path('/<int:book_id>', BookView.as_view()),
]딥러닝 서버와 연결
처음에 딥러닝 서버와 어떻게 연결을 해야할지 고민이 많았는데 python의 requests 라이브러리를 사용해 연결했다.
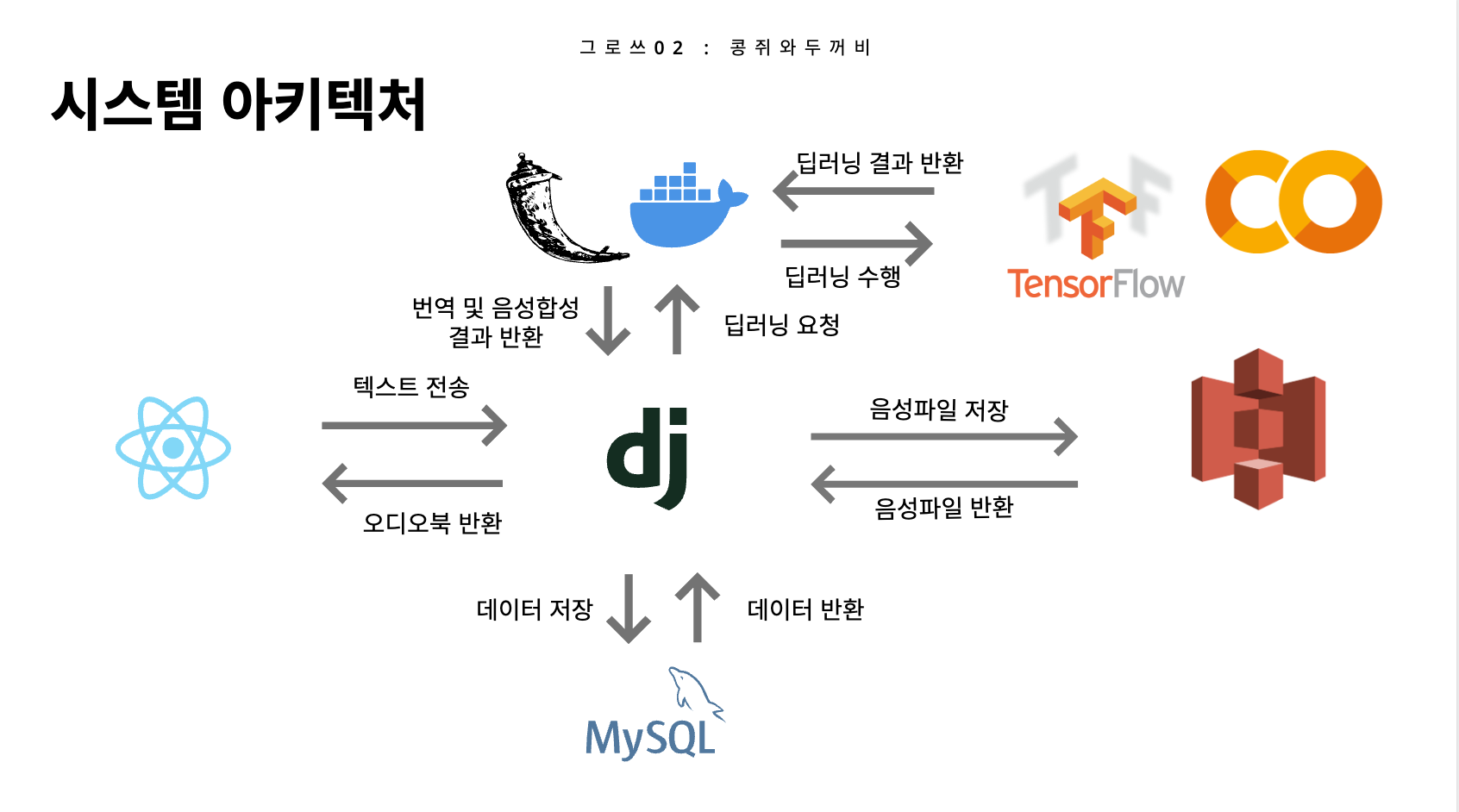
이게 우리 프로젝트의 시스템 아키텍처인데, 리액트에서 장고로 POST형태로 request를 보내면 장고에서 요청을 받아 python requests 라이브러리를 써서 플라스크로 요청을 보낸다. 플라스크에서는 기계번역과 음성합성을 거쳐서 생성된 텍스트와 음성파일을 장고로 전송하고 이를 MySQL에 저장하게 된다. GET 요청을 보낼 시에는 데이터베이스에서 바로 가져오기 때문에 플라스크를 거치지 않는다.
requests 사용
AWS 정보 같은 것들은 gitignore 하기 위해 따로 빼줬고, 다른 정보도 혹시 몰라 좀 가렸다. 파일이 직렬화돼서 전송되어 오기 때문에 역직렬화해주고 이를 s3에 올린다. 그 후 파일을 삭제한다.
- view.py
class BookListView(View):
s3_client = boto3.client(
's3',
aws_access_key_id=settings.AWS_ACCESS_KEY_ID,
aws_secret_access_key=settings.AWS_SECRET_ACCESS_KEY,
)
# 서재 전체 조회
def get(self, request):
books = Book.objects.all()
book_list = [{
"book_id": book.id,
"title": book.title,
} for book in books]
return JsonResponse({"RESULT": book_list}, status=200)
def handle_upload_mp3(self,f):
s3_client = boto3.client('s3',
aws_access_key_id=settings.AWS_ACCESS_KEY_ID,
aws_secret_access_key=settings.AWS_SECRET_ACCESS_KEY)
response = s3_client.upload_file(
f, {S3 버킷 이름}, f)
# 새로운 책 생성
def post(self, request):
data = json.loads(request.body)
title = data["title"]
text = data["text"]
text_process = requests.post(url='http://{플라스크서버 배포 ip 주소}/tts-server/api/process-text', json={'text': text})
jsonText = text_process.json()
strText = str(jsonText)[2:-2]
filename = "tts-audio"+str(uuid.uuid1()).replace('-','')+".wav"
with open(filename, "wb") as file: # open in binary mode
response = requests.post(url='http://{플라스크서버 배포 ip 주소}/tts-server/api/process-audio', json={'text': strText}) # get request
file.write(response.content) # write to file
self.handle_upload_mp3(filename)
file_url = "https://{S3 버킷 주소}/" + filename
os.remove(filename)
Book.objects.create(
title=title,
content=strText,
audio=file_url,
)
return JsonResponse({"title": title, "content": strText, "audio" : file_url}, status=201)Flask
사실 플라스크는 내가 메인으로 맡았던 부분이 아니라 자세히 설명은 못하지만 오류나는 부분을 서브로 도왔기 때문에 Docker compose를 사용해서 ec2 환경에서 배포하는 방법과 우리 프로젝트에서 인상깊었던 부분들에 대해서 이야기해보려 한다.
우리는 Dockerfile과 docker compose를 사용해서 배포를 하려했었는데 이 과정에서 많은 오류를 만났고... 맡았던 친구가 고생을 했는데 결국 배포에 성공했다.
배포하면서 만났던 문제는 크게
- 프로젝트 용량이 커서 GitHub에 안 올라감
- EC2 서버 터짐
이 있었다.
Docker Compose를 이용해서 배포하는 방법을 먼저 이야기 해보겠다.
Docker Compose를 이용하여 EC2 환경에서 배포하기
우선, Dockerfile과 docker-compose.yml 파일을 만들고 ec2 인스턴스를 올바르게 생성한 상황을 가정하고 그 후의 단계를 기술하려 한다.
Docker 설치
git clone으로 프로젝트를 복사해 온 후
git clone [클론할 깃허브 프로젝트 주소]우분투에 도커를 설치한다.
curl -fsSL https://get.docker.com/ | sudo sh
sudo systemctl status docker // 실행 중인지 확인
docker --version // 버전 확인docker --version을 실행했을 때 도커 버전이 뜨면 정상적으로 설치된 것이다.
Docker-compose 설치
다음으로 도커 컴포즈도 설치해준다.
sudo curl -L https://github.com/docker/compose/releases/download/1.25.0-rc2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose // 컴포즈 설치
sudo chmod +x /usr/local/bin/docker-compose // 권한설정
docker-compose --version // 버전확인프로젝트를 도커 컴포즈 컨테이너로 만듦
설치가 완료되면 프로젝트 디렉토리로 이동한다.
ls //디렉토리 구조 확인
cd [자기 디렉토리 이름]sudo docker-compose up이 명령어를 실행하고 정상적으로 동작된다면 배포를 성공한 것이다!
ec2 ip주소로 접속해보자.
우리가 배포하면서 마주친 문제들
프로젝트 용량이 커서 GitHub에 안 올라감
ec2 인스턴스에서 docker-compose up 명령어를 사용하려면 프로젝트를 GitHub 레포를 클론해서 받아와야 했는데 애초에 우리 딥러닝 서버의 용량이 너무 커서 깃헙에 올릴 수가 없었다...
그래서 고민하다가 내가 혹시 이렇게 하면 될까..? 싶어서 제안해봤는데 결론적으로 됐다. 간단한 방법인데 야매 방법으로 해결한 거 같긴 하다.
프로젝트를 압축해서 GitHub LFS로 올리고 이를 ec2 우분투에서 Unzip하여 사용한다 <- 이 방법이었다.
(여담이지만 배포하면서 인스턴스를 바꾸기도 해서(다음 이야기) 깃허브를 2-3번 정도 클론 받았더니 LFS bandwidth를 초과해서 LFS가 과금되긴 했다. 😂)
프로젝트 압축을 해제하면 일반 프로젝트 구조와 같아지기 때문에 그 후에는 일반적인 배포 방식을 사용하면 된다.
EC2 서버 터짐
처음에 프리티어 ec2를 사용했었는데 배포를 맡았던 친구 말에 의하면 docker-compose up 명령어 실행을 시키면 실행이 끝까지 안 되고 중간에 멈췄었다. 그래서 다음날에 내가 한번 해보려고 ec2 인스턴스에 ssh로 접속하려 했는데 자꾸 time out 되고 들어가지지 않았다.
우리 팀이 운이 좋게도 졸프 멘토님(졸업프로젝트 자체에 산업에 종사하시는 분과 멘토링을 연결해주는 제도가 있다)께서 AWS 강사로 일하시는 분이었어서 멘토님께 여쭤봤더니 인스턴스 CPU를 99-100%까지 사용해서 인스턴스가 뻗으면서 막힌 거라는 대답이 돌아왔다.
사실 우리 프로젝트는 딥러닝 모델이 두 개나 붙어있고 경량화는 고려하지 않고 만든 프로젝트였기 때문에 프리티어 ec2 인스턴스에서 돌아갈 리가 없었는데 우리의 과욕이었다..
정말 감사하게도 멘토님께서 iam user로 멘토님의 계정에 t3-large 인스턴스를 만들어서 사용하게 해주셨고, 결국 인스턴스를 바꿔서 배포에 성공했다!
인스턴스를 바꾸고 깃허브를 다시 클론 받는 과정에서 LFS가 6300원 과금됐지만 우리에겐 그 이상의 가치가 있었기 때문에 그저 너무 행복했고... 멘토님께 정말 감사했다.
팀장
어쩌다보니 내가 팀장이 되었다. 내가 하고 싶어서 했다기 보다도 내가 팀원들을 모았고 성격(조금은 나서는 편)이나 프로젝트 경험(없지는 않은 편)과 같은 걸 고려해서 자연스럽게 내가 되었던 거 같다.
사실 팀장을 만만하게 봤었는데 결론적으로 힘들었다. 장기간의 프로젝트를 이끈다는 게 쉽지는 않은 일이었다. 하는 거에 비해서 힘든 게 눈에 안 띄는 것 같기도 했고, 학교 측에서 행정적인 연락도 다 팀장에게 하기 때문에 자연스레 행정적인 부분도 내가 부담하는 부분이 많아졌다.
그치만 그만큼 프로젝트에 대한 책임감도 생기고 다른 파트에도 이리 기웃... 저리 기웃.. 하게 됐었어서 어떻게 하면 이 문제를 해결할 수 있을지 같이 고민했더니 좀 문제 해결 능력이 길러진 것 같다. (구글링 능력이 매우 향상된 거 같다)
또 원래는 내가 막 일정같은 거 잘 챙기는 편이 아닌데 내가 놓치면 팀 전체가 일정을 놓쳐버리는 게 되어버리기 때문에 일정을 몇번씩 다시 확인하다보니 졸프 일정말고도 내 일정도 잘 관리하게 되었다. 시험 기간 아니면 캘린더 어플을 쓰는 사람이 아니었는데 일정을 놓칠까봐 투두메이트를 열심히 쓰게 됐다.
결론적으로 힘들었던 만큼 개인적으로도 많이 성장했다!
마치며
일년 동안 졸업 프로젝트를 하며 평생 사용하지 않을 줄 알았던 기술들을 사용하고, 정말정말정말 많은 에러들을 만나고(컴퓨터공학과 입학 후 졸프 전까지 만났던 모든 에러들만큼의 에러들을 졸프 기간 1년동안 만났다고 해도 과언이 아니다) 이를 해결하면서 (아직 배울 점이 많지만)개발 능력이 조금은 향상한 것 같다.
개발은 마무리되었지만 아직 졸업발표나 포스터 제작이나 그 외에 다른 행정적인 과제들이 남아있는데 끝까지 잘 마무리 됐으면 좋겠다.

그럼, 졸프 개발 마무리를 자축하며 글을 마쳐야겠다!
참고링크
1.https://programmers-sosin.tistory.com/entry/Django-Django-%ED%81%B4%EB%9E%98%EC%8A%A4%ED%98%95-%EB%B7%B0-Generic-View-2?category=1063620
2.https://sce-tts.github.io/#/v1/requirement
3.https://sofar-sogood.tistory.com/entry/Glow-TTS-Glow-TTS-A-Generative-Flow-for-Text-to-Speech-via-Monotonic-Alignment-Search-NIPS-20?category=1013566
4.https://daily-coding-diary.tistory.com/m/14
'개발하자' 카테고리의 다른 글
| Java CS 지식 정리 (0) | 2022.07.04 |
|---|---|
| 암호 - 대칭 암호화에 대해서 (0) | 2022.06.05 |
| [Linux] Makefile 간단한 예제 (0) | 2021.11.29 |
| [Linux] shared library 사용하기 (0) | 2021.11.29 |
| [Linux] 두개의 분리된 파일을 하나의 실행파일로 합치는 과정 (0) | 2021.11.29 |
